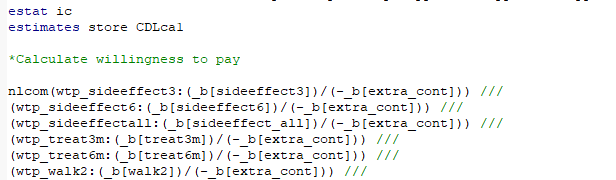
I’m very excited to share our new paper, showing Australian women are divided on the use of artificial intelligence (AI) in breast cancer screening. While AI has the potential to enhance the accuracy of mammogram reviews and reduce healthcare costs, many women remain sceptical. Our study, which used a discrete choice experiment to survey over ...